In this interview, Valerii Chetvertakov, a graduate of ML Zoomcamp, tells us about:
- His work in property valuation and interest in machine learning
- The main challenges of entering the fields of ML and data
- Machine Learning Zoomcamp
- Valerii’s internship project: extracting business relationships between companies
- Suggestions for the future students
Please tell us a bit about yourself. What’s your background?
I have a higher technical education, specialising in underground mining of mineral deposits. Later, I switched to the field of property valuation. I have been a certified appraiser since 2006.
When and how did it occur to you that you’re interested in ML?
Working as an appraiser on various equipment, goods and real estate valuation projects, I came across the probabilistic nature of market values and prices.
I had to apply various statistical and regression approaches in property valuation to deal with a lack of sufficient data, variety of property features, and uncertainty. I enjoyed learning such techniques and wanted to explore this outlet professionally. My property valuation reports looked like a mathematical reference — a lot of formulas, calculations, tables, graphs.

When doing property valuation, we need to take into account a lot of features (Image generated with DALL-E)
At some point, the capabilities of Microsoft Excel became insufficient for me to analyse the data and build statistical and regression models. Then I learned about Python and Machine Learning.
In the summer of 2018, I decided to learn Python, and in September I enrolled in an evening course on Machine Learning basics, organised by a local IT school.
What did you do to enter the field and what were your main challenges?
First, I consumed a lot of introductory information about machine learning and data science — where, why and how Machine Learning is applied, what are the current achievements, and future challenges. I was amazed at how widely Machine Learning was introduced into our lives, and what great prospects it holds for business, technology, and humanity. We need to find that sense of belonging to something great and outstanding in order to overcome obstacles when pursuing a goal. I got that feeling from the start.
Next, I found a mentor, Artem Gruzdev from Moscow, who helped me to sort through the field of classical Machine Learning. Self-study has its drawbacks, as at some point, you do not have enough knowledge, experience, or wisdom to move forward. You get stuck. Therefore, I think that having a mentor is a big advantage.

Having a mentor can help move forward (Image generated with DALL-E)
Additionally, I attended many online courses, read/watched many tutorials, and studied some books. After a year of such self-education and with the help of my mentor, I planned a dedicated path and began to choose courses more wisely.
Still, the main challenge for me was the practical application of acquired knowledge. I tried taking part in Kaggle competitions, but honestly speaking, this is a second job and requires a lot of time and resources. The benefits of Kaggle is that you get good practical experience, even on well studied tutorial datasets. One of these datasets I later used for my midterm project in Machine Learning Zoomcamp.
To be more competitive on the data science job market, I began to dive into Deep Learning and NLP. So from the spring of 2020, I began to take courses on Neural Nets and NLP during which I explored and met trials with neural networks theory, backpropagation, Pytorch, architectures of RNNs, CNNs and transformers.
What attracted you to Machine Learning Zoomcamp? Why did you decide to take it?
While studying Computer Vision with Deep Learning, I wanted to refresh my ML knowledge and improve skills in practical deployment. The syllabus of ML Zoomcamp, and the community around it — DataTalks.Club — looked great for me, so I enrolled. My expectations were absolutely exceeded. I also had my first experience in peer-to-peer review of other students’ projects and in going public in social networks about what you’ve learned.

Valerii sharing his progress on social media
What do you do now? Can you tell us more about the internship that you got and the work you needed to do?
Thanks to ML Zoomcamp, I got an internship at an AI start-up, delphai, that is focused on extracting, analysing, and structuring firmographic data.
My internship project was to extract information from texts. I worked on detection and extraction of business relations between companies. The task is, given a sentence and a pair of tagged entities, to predict the relation between those entities and the direction of the relation.
For example, there is a sentence in the news article “EL SEGUNDO, Calif., June 21, 2022 — EV Connect, Inc., a premier electric vehicle (EV) charging solution provider, announced that it has been acquired by Schneider Electric, the leader in energy management and automation.”, the relation between two companies is about acquisition, and the direction is Schneider Electric | EV Connect, Inc. | Acquirer - Acquired.
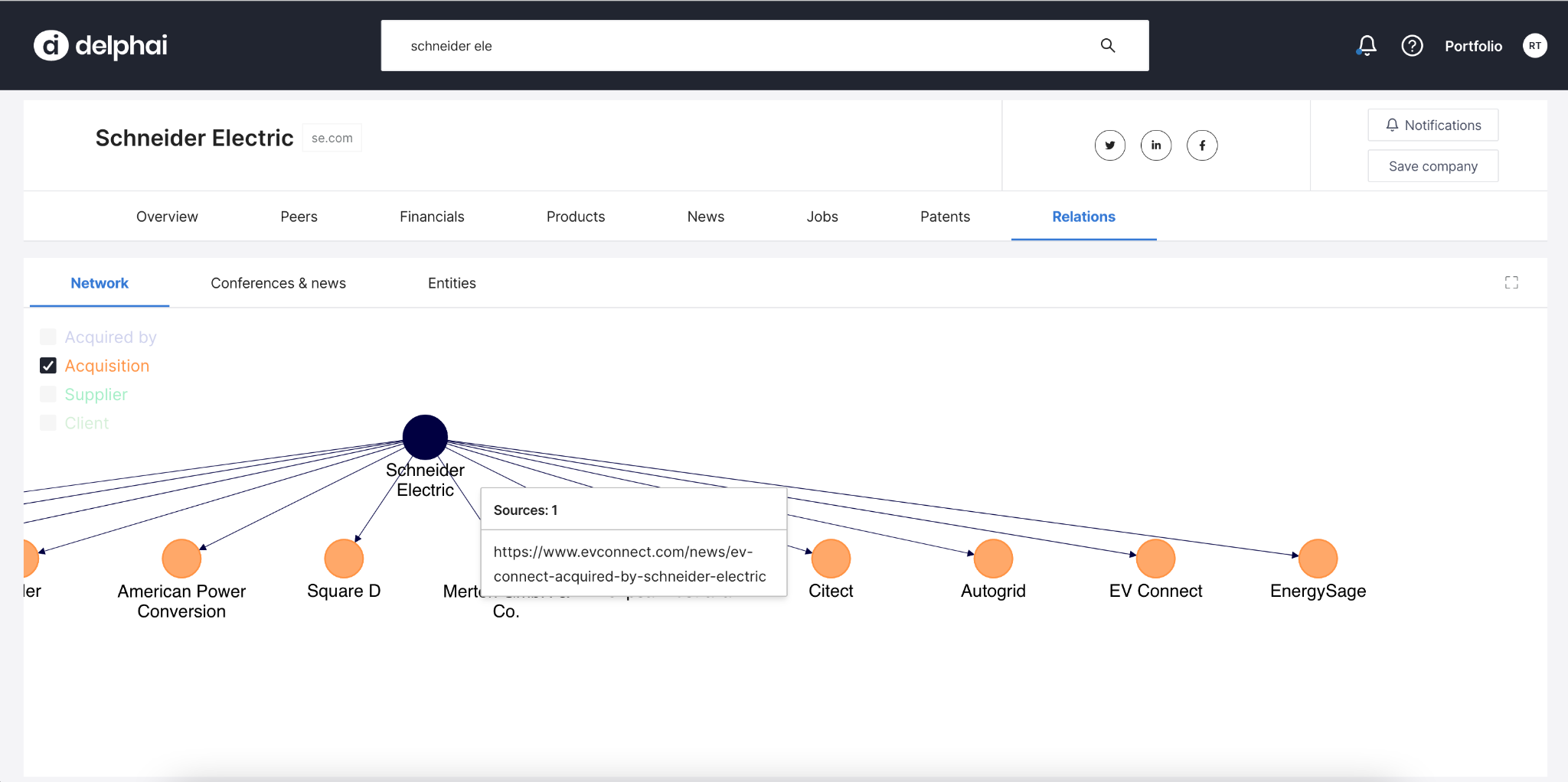
A screenshot from delphai showing the discovered relationships
Relationship extraction is one of the hottest NLP tasks now. I was able to experience the essential steps of the ML cycle – from dataset creation and annotation to model deployment and serving. It was an invaluable practical experience for me to work with databases, Azure storage, annotation tools, Github and so much more during the project.
As a result of the project the service for partnership relation extraction was deployed and included into “news-relation-extraction” service. Initially, I used Spacy pipelines with transformer models for my project, but recently, we switched to a more sophisticated and promising approach.
Do you have any suggestions for future students of ML Zoomcamp?
If you are a total beginner and starting self-education, here are my suggestions:
- Try to get a mentor or supervisor;
- Plan your path;
- Follow professionals on social networks like Twitter or Telegram;
- Group up during courses with other students and communicate;
- If you are non-native English speaker like me, find time for translating English articles or tutorials on topics your are studying to your language;
- Although there are a lot of free courses and materials, don’t hesitate to pay for tuition if you are sure it is worth it and you need it. You will also feel more responsible for outcome;
- A lot of coding practice is a must;
- Keep the motivation! If you don’t feel like studying or coding, follow the advice of Daniel Bourke, a self-taught Machine Learning Engineer and enthusiast, “Ask yourself: What’s the alternative not to study?”
What kind of other materials would you recommend?
My first introductory book was “An Introduction to Statistical Learning with Applications in R” by Trevor Hastie Et al. As for Python and Pandas I’d recommend books by Ted Petrou and Matt Harrison.
ML practitioner - Abhishek Thakur, his YouTube channel and book. In general, YouTube is a great supplementary source of information and tutorials, use it wisely. Don’t forget to subscribe and give a like!
As for NLP, a good starting point is the bestseller “Speech and Language Processing” by Daniel Jurafsky and James H. Martin, there was a third edition in 2020.
As for coding practice, the best material is a package / library documentation!
What was the most helpful thing for you in the ML Zoomcamp course?
- Office hours - the feedback from lecturer on home tasks is essential;
- Slack channel;
- Alexey’s drawings during lectures.
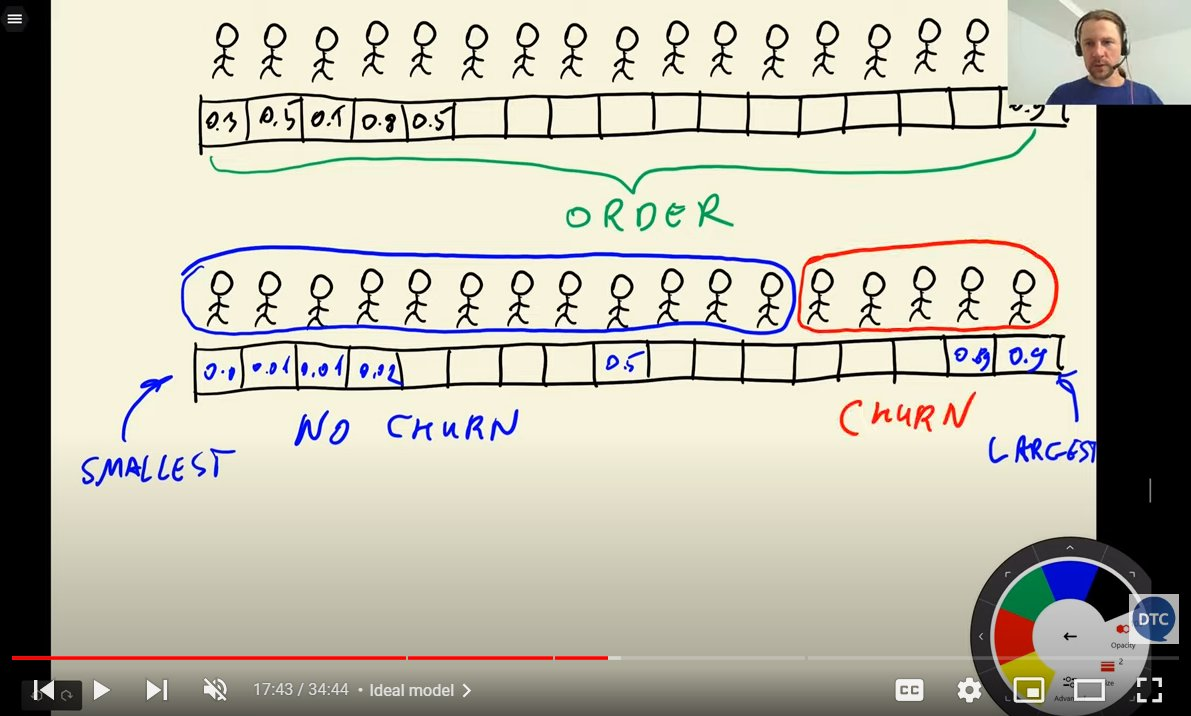
An illustration for ROC curves from Machine Learning Zoomcamp
Anything else you’d like to mention?
I take this opportunity to thank everyone involved in the ML Zoomcamp creation and who kept it going. Congratulations on great continuations with DE Zoomcamp and MLOps Zoomcamp!
Machine Learning Zoomcamp is open for registrations. Sign up here.
About delphai: delphai collects unstructured public company data all over the internet and then uses ML and AI to transform this unstructured data into a structured format to make it searchable and usable for our customers.