Lecture 1.1: Introduction to Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG)
Table of Contents
- Course Focus
- What Problem Will We Solve During This Course?
- Our Solution Approach
- Understanding Large Language Models: The Foundation
- The Limitation of LLMs: The Knowledge Cutoff Problem
- Introducing RAG: The Solution to LLM Limitations
- The Strength We’ll Leverage: RAG’s Modular Architecture
- What You’ll Build in This Course
- Beyond This Course
- Key Takeaways
Welcome to LLM Zoomcamp, where we begin a practical journey into the world of Large Language Models (LLMs) and their real-world applications.
Course Focus
[!NOTE] This course isn’t a theoretical deep-dive into the mathematics behind neural networks. Instead, it’s a hands-on exploration of how we can use these powerful tools to solve real problems.
We will focus on building practical systems that can answer questions intelligently by combining the power of modern language models (LLMs) with information retrieval techniques like Retrieval-Augmented Generation (RAG).
What Problem Will We Solve During This Course?
LLM Zoomcamp is DataTalks.Club’s fifth course, building upon our tradition of practical, project-based learning. As our community has grown across multiple specialized courses, we’ve accumulated extensive knowledge bases in the form of FAQ documents.
These documents represent thousands of hours of collective knowledge: questions asked by previous students and carefully crafted answers by instructors and teaching assistants. They’re invaluable resources that could save new students significant time and reduce repetitive questions in our community channels.
Here are the FAQs from our first three courses:
- Data Engineering Zoomcamp FAQ: A comprehensive 321-page document filled with student questions and detailed answers
- ML Zoomcamp FAQ: An equally extensive FAQ covering machine learning concepts and practical issues
- MLOps Zoomcamp FAQ: Specialized Q&A focused on MLOps practices and tools
But here’s the challenge: How does a student actually find an answer when the FAQ is so massive? It’s like finding a needle in a haystack.
Picture this scenario: A new student joins our Data Engineering Zoomcamp and needs to know “How do I set up my development environment on Windows?” They’re looking for a quick answer.
To find that answer, they could:
- Manually search through 321 pages of FAQ
- Use basic text search (Ctrl+F) with limited effectiveness
- Give up and ask the question again in our Slack channel (creating duplication)
As a result, they might miss out on the detailed, high-quality answer that already exists in the FAQ and create unnecessary duplication. This scenario plays out daily across technical communities worldwide. The knowledge exists, but discovery is the bottleneck.
Our Solution Approach
What if we could build an intelligent assistant that:
- Understands the intent behind a student’s question
- Quickly searches through our entire knowledge base
- Finds the most relevant information
- Provides a comprehensive, contextual answer in natural language
This is exactly what we’ll build in this course. But to get there, we first need to understand the technology that makes it all possible.
Understanding Large Language Models: The Foundation
To build our intelligent Q&A system, we first need to understand the foundational technology: Large Language Models.
What Are Language Models?
Language models aren’t new—you use them every day without even thinking about it. Every time you type on your phone and see those predictive text suggestions? That’s a language model at work.
Example: When you type “How are” in WhatsApp, your phone suggests “you” as the next word because it has learned from patterns that “How are you?” is a common phrase.
These simple models work through basic statistical methods:
- They analyze the frequency of word combinations
- They predict the most likely next word based on previous words
- They use techniques like Naive Bayes classification
- They have relatively few parameters (thousands to millions)
While effective for their purpose, these models are quite limited. They can’t understand context deeply, handle complex reasoning, or maintain coherent conversations.
The “Large” in Large Language Models
The breakthrough came with models that are “large” in multiple dimensions:
1. Scale of Parameters: Instead of thousands of parameters, LLMs have billions or even trillions. To put this in perspective:
- Simple phone autocomplete: ~100,000 parameters
- GPT-3: 175 billion parameters
- GPT-4: Estimated 1+ trillion parameters
2. Training Data Volume: LLMs are trained on massive datasets containing:
- Books, articles, and academic papers
- Web pages and forums
- Code repositories
- Reference materials and encyclopedias
- Conversations and Q&A pairs
3. Computational Architecture: Modern LLMs use transformer architectures that can:
- Process long sequences of text
- Understand relationships between distant words
- Maintain context across lengthy conversations
- Perform reasoning-like operations
The Emergence of Intelligence-Like Behavior
Here’s what makes LLMs truly remarkable: even though they’re basically “next word predictors,” their massive scale allows them to do things that feel genuinely intelligent.
When you interact with ChatGPT, Claude, or similar models, you experience:
- Contextual understanding: They grasp what you’re asking, even with ambiguous phrasing
- Knowledge synthesis: They combine information from different domains
- Reasoning patterns: They can work through multi-step problems
- Adaptive communication: They adjust their response style to match your needs
[!NOTE] In this course, we’ll treat LLMs as “black boxes.” We won’t get into the technical details of how they work under the hood. Instead, we’ll focus on how to use these powerful tools effectively.
How LLMs Process Your Requests
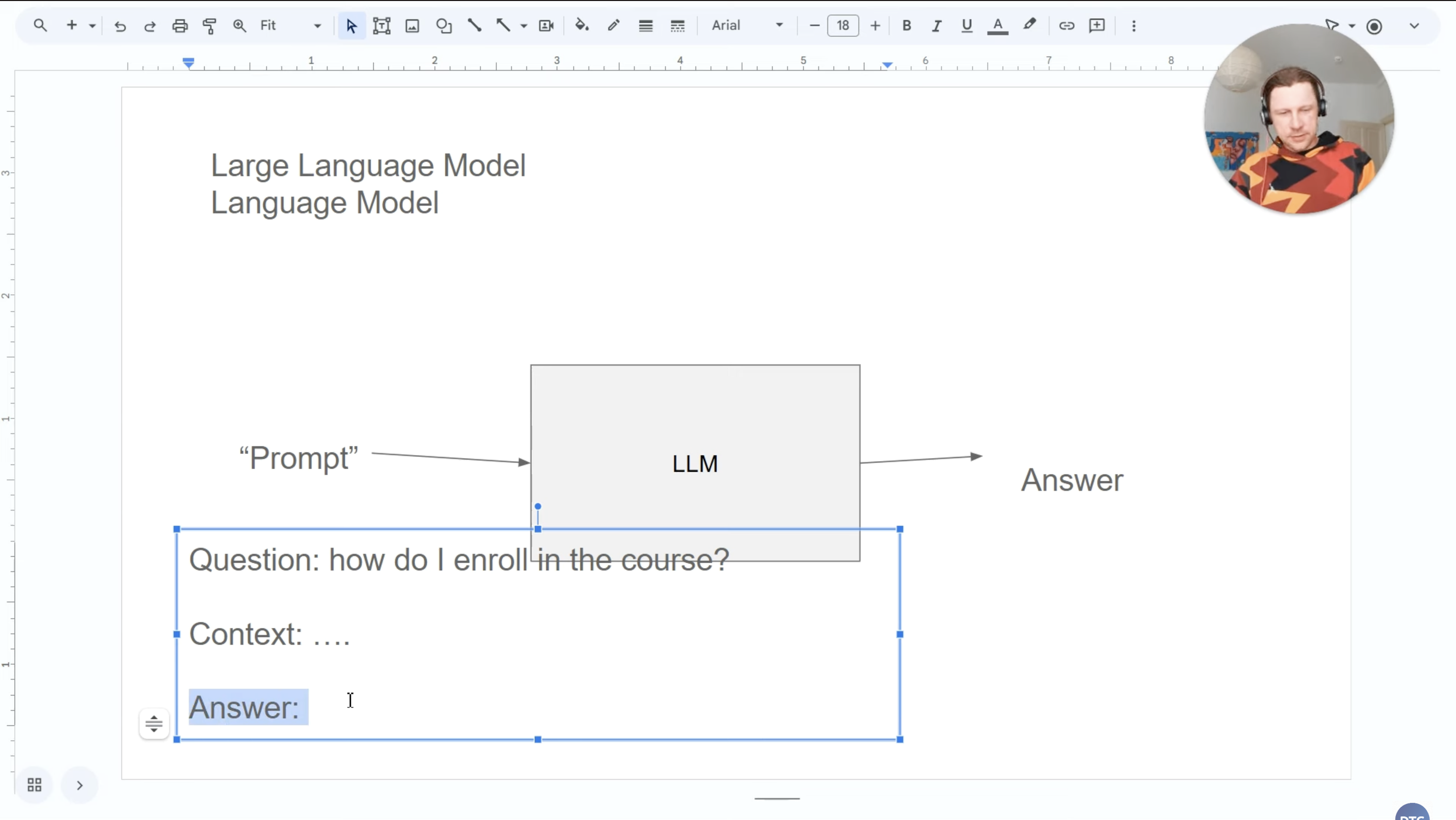 Figure 1: LLM Processing
Figure 1: LLM Processing
Understanding the basic input-output flow helps us use LLMs more effectively:
Your Input (Prompt) → [LLM Processing] → Generated Response
The Prompt: This is your input text. LLMs interpret everything as a completion task. Even when you ask a question, the model is essentially completing the pattern of “Question: [your question] Answer: [response]”
Example Interaction:
Input: "Explain how photosynthesis works"
Internal Processing: The LLM recognizes this as a request for explanation and begins generating a response that would logically complete this prompt.
Output: "Photosynthesis is the process by which plants convert sunlight, carbon dioxide, and water into glucose and oxygen..."
The Limitation of LLMs: The Knowledge Cutoff Problem
Now that we know what LLMs can do, let’s talk about their biggest limitation—and why we need something more to solve our FAQ problem.
Here’s the thing: LLMs have one major constraint. Their knowledge gets frozen when they finish training. Let’s see what this means:
Scenario 1 - Perfect LLM Performance:
Question: "How do I cook salmon?"
LLM Response: Provides detailed cooking instructions, temperature guidelines, timing recommendations, etc.
This works perfectly because cooking salmon is well-documented in the LLM’s training data.
Scenario 2 - LLM Knowledge Gap:
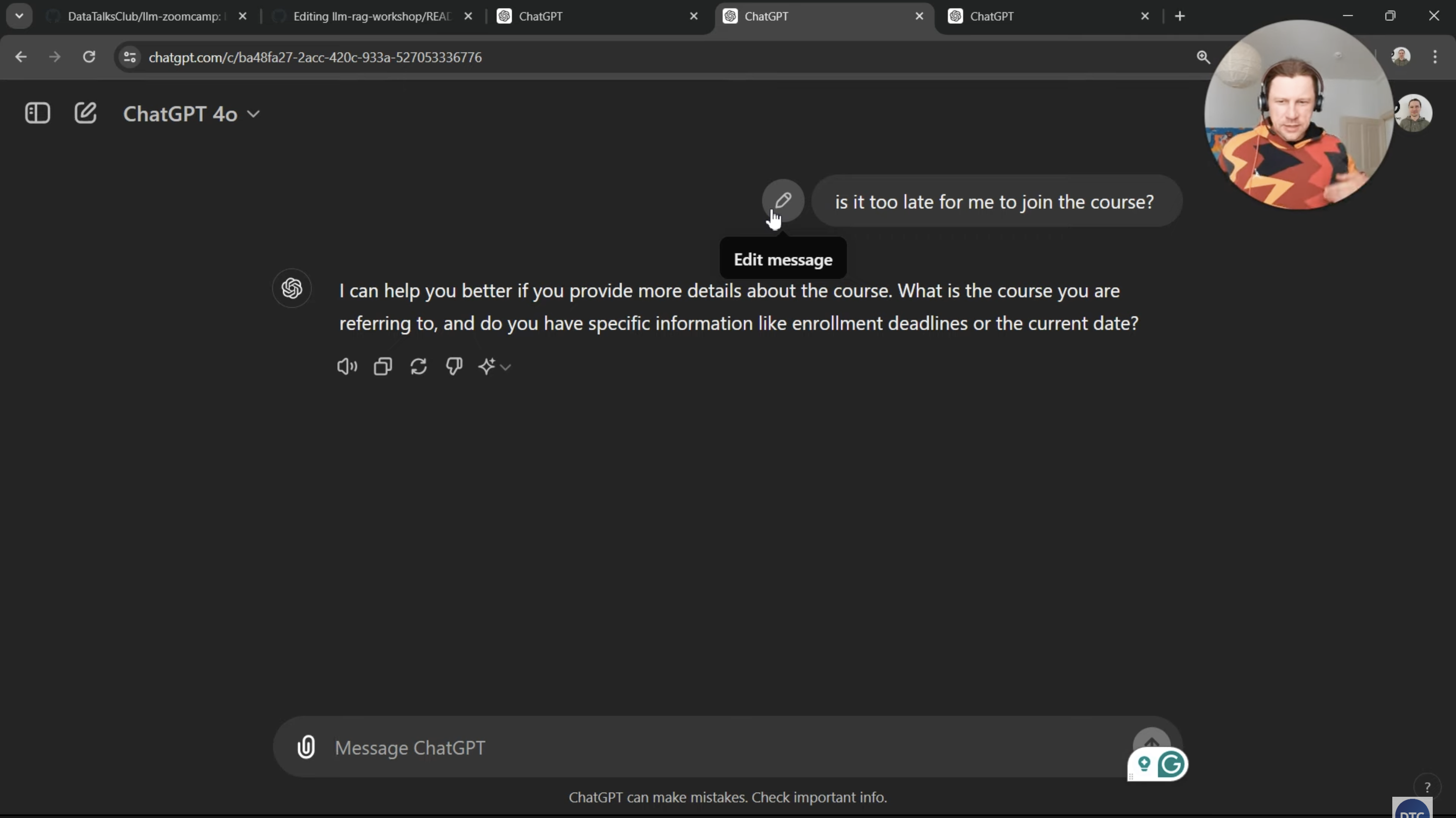
Question: "Is it too late to join the Data Engineering Zoomcamp?"
LLM Response: "I'd be happy to help, but I need more information. Which Data Engineering program are you referring to, and what is the current date?"
The LLM has no context about:
- Which specific course you mean
- Current enrollment periods
- Course-specific policies
- Real-time availability
Why This Matters for Our FAQ System
If we just connected students directly to ChatGPT, they’d get generic answers that miss:
- Course-specific requirements
- Specific tools and versions we use
- Our particular setup procedures
- Community-specific conventions
- Current course policies and deadlines
We need to give the LLM access to our specific knowledge so it can provide accurate, helpful answers.
Introducing RAG: The Solution to LLM Limitations
RAG (Retrieval-Augmented Generation) solves this problem. It’s the key technique we’ll master in this course.
What is RAG?
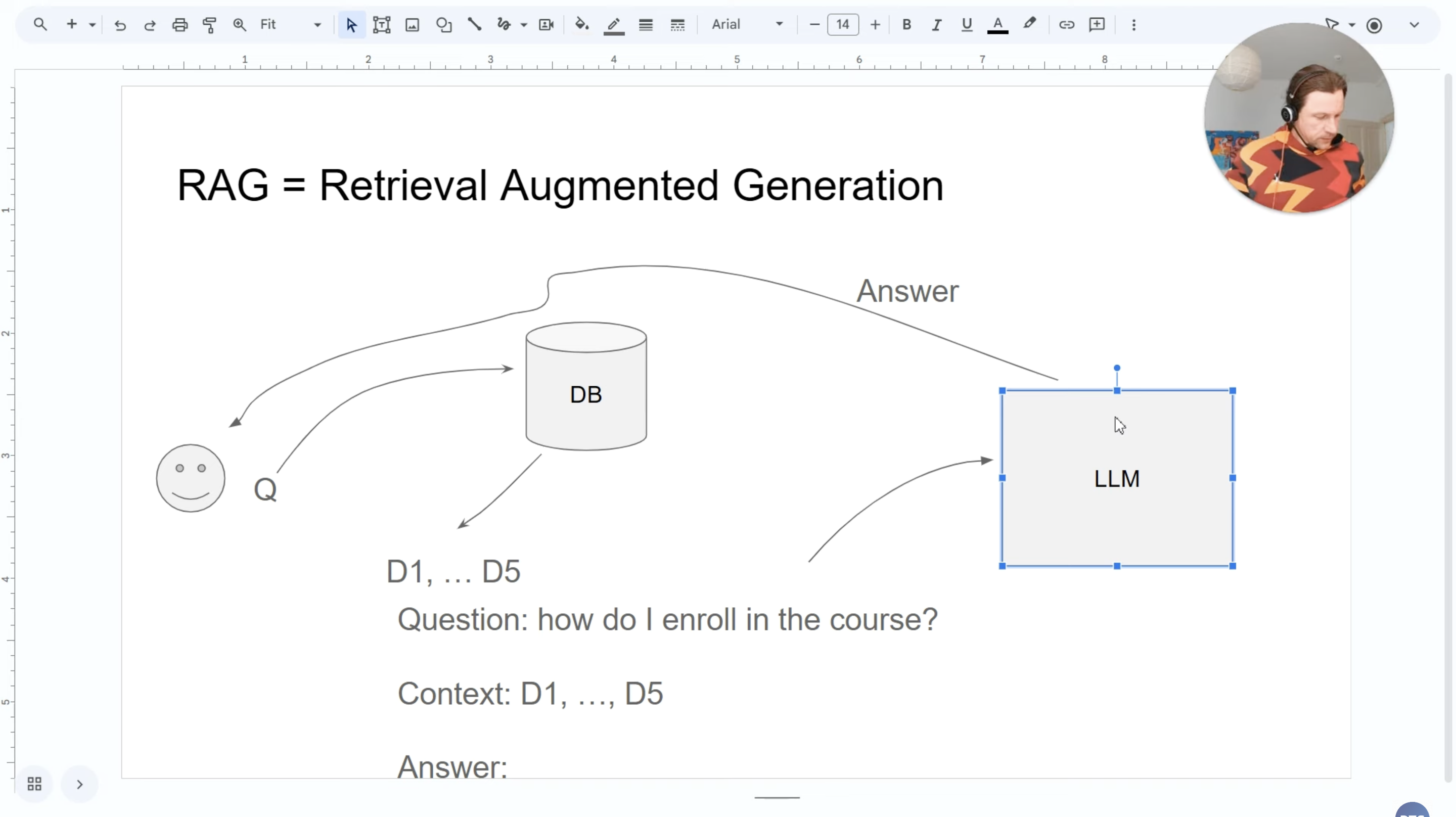
RAG = Retrieval (Search) + Augmented (Enhanced) + Generation (LLM)
The idea is beautifully simple: instead of expecting the LLM to know everything, we feed it the right information at just the right moment.
Here’s the magic: RAG turns LLMs from smart generalists into domain experts.
How RAG Works: A Complete Walkthrough
Let’s walk through exactly how RAG would handle our FAQ problem:
Student Question → Knowledge Base Search → Document Retrieval → Context Enhancement → LLM Generation → Comprehensive Answer
Step-by-Step Process:
1. User initiates a query:
Student asks: "How do I enroll in the Data Engineering Zoomcamp?"
2. Query processing and search: The system takes this question and searches our FAQ knowledge base. This isn’t just simple text matching—it looks for semantically relevant content that might answer the question, even if the exact words don’t match.
3. Document retrieval: The search returns multiple relevant documents:
- Document 1: “Registration process and deadlines”
- Document 2: “Prerequisites and requirements”
- Document 3: “Course schedule and format”
- Document 4: “Payment and enrollment FAQ”
- Document 5: “Technical setup requirements”
4. Context assembly: The system creates an enhanced prompt:
Question: How do I enroll in the Data Engineering Zoomcamp?
Context:
[Document 1 content]: Registration opens on January 15th for each cohort. Students can register through the course website by filling out the enrollment form...
[Document 2 content]: Prerequisites include basic programming knowledge in Python and familiarity with command line...
[Document 3 content]: The course runs for 8 weeks with live sessions every Monday and Wednesday...
[Additional relevant context from Documents 4 and 5]
Answer:
5. LLM generation: The LLM now has both the original question and rich context from our specific knowledge base. It generates a comprehensive answer that addresses:
- Specific enrollment steps
- Current deadlines and dates
- Prerequisites and expectations
- What to expect from the course format
- Any technical requirements
6. Response delivery: The student receives a detailed, accurate answer that’s specifically tailored to our Data Engineering Zoomcamp, not generic advice about online courses.
See what happened? The same LLM that couldn’t answer course-specific questions before is now giving expert-level responses. Context is the secret ingredient.
The Strength We’ll Leverage: RAG’s Modular Architecture
One of RAG’s best features: it’s modular. This means we can swap out different parts and experiment as we go.
We’ll start simple and work our way up:
Week 1: We’ll start with a simple, custom search engine to understand the fundamentals
- Build a basic keyword-based search
- Learn how document indexing works
- Understand relevance scoring
Week 2: We’ll upgrade to Elasticsearch
- Professional-grade search capabilities
- Advanced query processing
- Better performance and scalability
Future Modules: We’ll explore vector search
- Semantic similarity instead of just keyword matching
- Handle synonyms and conceptual queries
- More sophisticated relevance understanding
We can swap these search technologies without changing the overall architecture. Each approach has trade-offs:
- Simple search: Easy to understand, limited capability
- Elasticsearch: Professional features, more complex setup
- Vector search: Most sophisticated, requires additional infrastructure
Interchangeable LLM Components
The modular approach also applies to the language model component:
Module 1 Approach: We’ll use OpenAI’s models (GPT-3.5/GPT-4)
- High-quality responses
- Easy API integration
- Paid service
Alternative Options: The same RAG framework works with:
- Open-source models (Llama, Mistral, etc.): Free but require more setup
- Local models (via Ollama): Complete privacy and control
- Other commercial APIs (Claude, Gemini, etc.): Different strengths and pricing
The Flexibility Advantage: You can experiment with different combinations:
- Elasticsearch + GPT-4 for maximum capability
- Simple search + local LLM for complete privacy
- Vector search + Claude for cost optimization
What You’ll Build in This Course
By the time you finish this course, you’ll have built a complete, production-ready RAG system with:
Technical Components:
- A robust search and retrieval system
- LLM integration with proper prompt engineering
- A user-friendly web interface
- Error handling and system monitoring
Practical Skills:
- How to evaluate and improve RAG system performance
- Techniques for handling different types of queries
- Methods for updating and maintaining knowledge bases
- Best practices for deploying RAG applications
Real-World Application:
- A working Q&A system for any knowledge base you choose
- The ability to adapt the system to new domains
- Understanding of when and how to use RAG effectively
Beyond This Course
The skills you’ll learn here go way beyond FAQ systems.
You can use such chatbots in:
- Customer Support: Automated response systems that understand product documentation
- Internal Knowledge Management: Help employees find information across company documents
- Research Assistance: Systems that can synthesize information from academic papers
- Code Documentation: Tools that help developers understand large codebases
- Educational Platforms: Intelligent tutoring systems that can answer domain-specific questions
- Legal and Compliance: Systems that can navigate complex regulatory documents
Key Takeaways
As we wrap up this introduction, here are the key points to remember:
LLMs are Powerful but Limited: Large Language Models can generate human-like text but are constrained by their training data cutoff and lack domain-specific knowledge.
RAG Bridges the Knowledge Gap: By combining search with generation, RAG provides LLMs with just-in-time access to relevant, specific information.
Modular Architecture Enables Innovation: RAG’s component-based design allows continuous improvement and experimentation with different search and LLM technologies.
Real-World Problem Solving: This course emphasizes practical application—you’ll solve genuine problems that exist in educational and business contexts.
The Future is Augmented Intelligence: RAG represents a broader trend toward systems that combine AI reasoning with accurate information retrieval.
Scalable Knowledge Systems: The techniques you learn can be applied to any domain where accurate, contextual information retrieval is important.
Remember, we’re learning to solve real problems that affect real people. Every system you build could save someone hours of frustration and help them find exactly what they need.
Ready? Let’s dive in and build your first RAG system!# Lecture 1.1: Introduction to Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG)